







 See Also
See Also
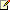 Important: Important: |
|---|
| This is retired content. This content is outdated and is no longer being maintained. It is provided as a courtesy for individuals who are still using these technologies. This content may contain URLs that were valid when originally published, but now link to sites or pages that no longer exist. |
Written languages are represented by textual elements — called code elementsor characters — that are used to create words and sentences. These elements can be letters such as sor V,characters such as those used in Japanese Hiragana to represent syllables, or ideographs such as those used in Chinese to represent full words or concepts.
A code element is an abstract concept, defined as the smallest part of a written language that has semantic value. A single 16-bit number is assigned to each code element defined by the Unicode standard. Each of these 16-bit numbers is called a code value and, when referred to in text, is listed in hexadecimal form following the prefix U. For example, the code value U+0041 is the hexadecimal number 0041, which is equal to the decimal number 65. It represents the character A in Unicode.
Each code element is also assigned a unique name that specifies it and no other. For example, U+0041 is assigned the character name LATIN CAPITAL LETTER A. U+0A1B is assigned the character name GURMUKHI LETTER CHA.
Code elements are grouped logically throughout the range of code values, which is called the codespace. The coding begins at U+0000 with standard ASCII characters, and then continues with Greek, Cyrillic, Hebrew, Arabic, Indic, and other scripts. Then symbols and punctuation are inserted, followed by Hiragana, Katakana, and Bopomofo. The complete set of modern Hangul appears next, followed by the unified ideographs. The end of the codespace contains code values that are reserved for further expansion, private use, and a range of compatibility characters.
The following illustration shows Unicode's encoding layout.

The Unicode standard defines how characters are interpreted. It is not responsible for rendering characters on screen or paper. The software or hardware is responsible for the appearance of the characters on the screen or in print. For example, the character identified by a Unicode code value as BENGALI DIGIT 5 is an abstract entity. The mark made on the screen or paper — called a glyph —is a visual representation of the character. The Unicode standard does not define the glyph image. It does not specify the size, shape, or orientation of the character. It simply defines how the character is interpreted by the software or target device.
Occasionally, you may choose to render multiple characters together. This is referred to as creating a composite character. For example, "â" is a composite character created by rendering "a" and "^" together. A composite character is typically made up of a base letter, which occupies a single space, and one or more non-spacing marks, which are rendered in the same space as the base letter.
The Unicode standard specifies the order of characters used to create a composite character. The base character comes first, followed by one or more non-spacing marks. If a code element is encoded with more than one non-spacing mark, you can render the non-spacing marks in any order as long as the marks do not interact typographically. If they do interact, the order must be considered. The Unicode standard specifies how competing non-spacing characters are applied to a base character.
As an alternative to rendering your own composite characters, the Unicode standard offers pre-composed characters to retain compatibility with established standards such as Latin 1, which includes many pre-composed characters such as "ü" and "ñ". Each pre-composed character is represented by a single code value, rather than two or more code values that may combine during rendering. For example, the character "ü" can be encoded as the single code value U+00FC "ü" or as the base character U+0075 "u" followed by the non-spacing character U+0308 "¨".
Pre-composed characters may also be decomposed. For example, an application importing a text file containing the pre-composed character "ü" may decompose that character into a "u" followed by the non-spacing character "¨". This allows easy alphabetical sorting for languages where character modifiers do not affect alphabetical order. The Unicode standard defines decomposition for all pre-composed characters.